 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-SCANet: A Multiscale Transformer-Based Architecture with Dual Attention for No-Reference Image Quality Assessment
Feb 03, 2026We present the Multi-Scale Spatial Channel Attention Network (MS-SCANet), a transformer-based architecture designed for no-reference image quality assessment (IQA). MS-SCANet features a dual-branch structure that processes images at multiple scales, effectively capturing both fine and coarse details, an improvement over traditional single-scale methods. By integrating tailored spatial and channel attention mechanisms, our model emphasizes essential features while minimizing computational complexity. A key component of MS-SCANet is its cross-branch attention mechanism, which enhances the integration of features across different scales, addressing limitations in previous approaches. We also introduce two new consistency loss functions, Cross-Branch Consistency Loss and Adaptive Pooling Consistency Loss, which maintain spatial integrity during feature scaling, outperforming conventional linear and bilinear techniques. Extensive evaluations on datasets like KonIQ-10k, LIVE, LIVE Challenge, and CSIQ show that MS-SCANet consistently surpasses state-of-the-art methods, offering a robust framework with stronger correlations with subjective human scores.
* Published in ICASSP 2025, 5 pages, 3 figures
Convolutions Need Registers Too: HVS-Inspired Dynamic Attention for Video Quality Assessment
Jan 16, 2026No-reference video quality assessment (NR-VQA) estimates perceptual quality without a reference video, which is often challenging. While recent techniques leverage saliency or transformer attention, they merely address global context of the video signal by using static maps as auxiliary inputs rather than embedding context fundamentally within feature extraction of the video sequence. We present Dynamic Attention with Global Registers for Video Quality Assessment (DAGR-VQA), the first framework integrating register-token directly into a convolutional backbone for spatio-temporal, dynamic saliency prediction. By embedding learnable register tokens as global context carriers, our model enables dynamic, HVS-inspired attention, producing temporally adaptive saliency maps that track salient regions over time without explicit motion estimation. Our model integrates dynamic saliency maps with RGB inputs, capturing spatial data and analyzing it through a temporal transformer to deliver a perceptually consistent video quality assessment. Comprehensive tests conducted on the LSVQ, KonVid-1k, LIVE-VQC, and YouTube-UGC datasets show that the performance is highly competitive, surpassing the majority of top baselines. Research on ablation studies demonstrates that the integration of register tokens promotes the development of stable and temporally consistent attention mechanisms. Achieving an efficiency of 387.7 FPS at 1080p, DAGR-VQA demonstrates computational performance suitable for real-time applications like multimedia streaming systems.
How deep is your encoder: an analysis of features descriptors for an autoencoder-based audio-visual quality metric
Mar 24, 2020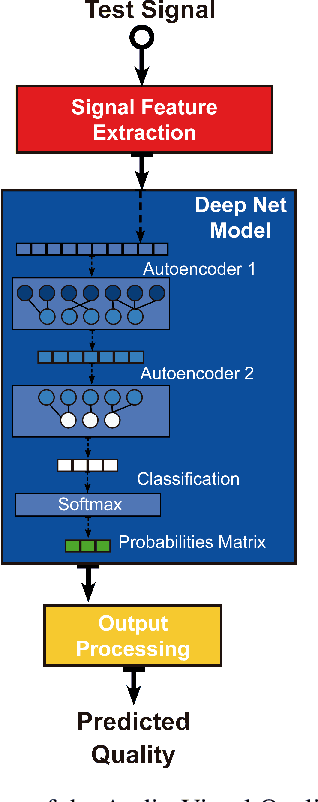
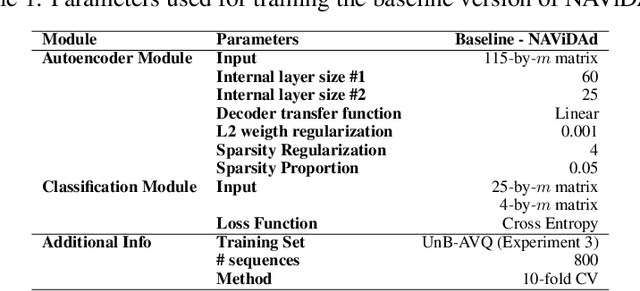
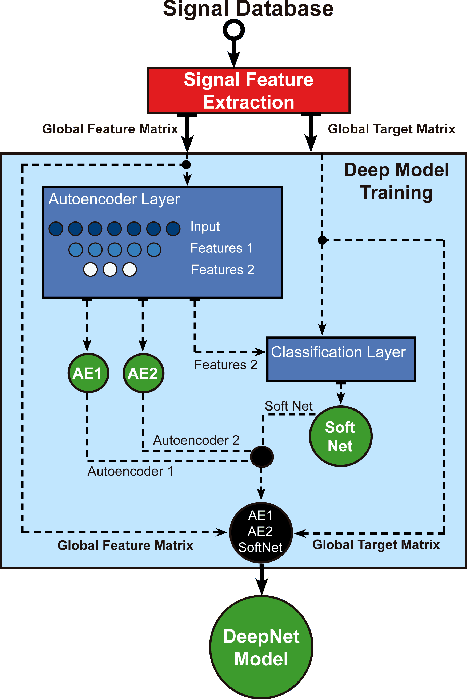
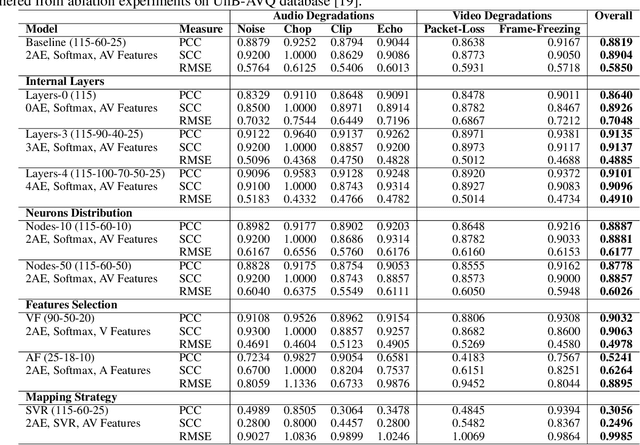
The development of audio-visual quality assessment models poses a number of challenges in order to obtain accurate predictions. One of these challenges is the modelling of the complex interaction that audio and visual stimuli have and how this interaction is interpreted by human users. The No-Reference Audio-Visual Quality Metric Based on a Deep Autoencoder (NAViDAd) deals with this problem from a machine learning perspective. The metric receives two sets of audio and video features descriptors and produces a low-dimensional set of features used to predict the audio-visual quality. A basic implementation of NAViDAd was able to produce accurate predictions tested with a range of different audio-visual databases. The current work performs an ablation study on the base architecture of the metric. Several modules are removed or re-trained using different configurations to have a better understanding of the metric functionality. The results presented in this study provided important feedback that allows us to understand the real capacity of the metric's architecture and eventually develop a much better audio-visual quality metric.